취향 컴파일러
생성 시스템을 위한 실시간 취향 추론을 어떻게 만들 것인가
영어 원문에서 옮김 · 기계 초벌 번역, 검수 전
Taste Model 연작의 2부. 1부는 스칼라 보상이 봉우리를 깎아 평평하게 만든다는 점을 짚었다. 이 글은 그 대안을 짓는다.
음악 생성기에 프롬프트를 넣는다. 여덟 개의 클립이 돌아온다. 대부분은 무난하고 평범하게 들린다. 나는 피아노가 듬성듬성하고 드럼이 절제된 하나를 고른다. “리버브를 줄이고 저역을 더 단단하게”라고 입력한다. 다음 묶음이 도착한다. 더 가까워졌다. 다시 고르고, 다시 손본다. 두 차례 더. 그렇게 나온 결과는 만일 내게 기량이 있었다면 내가 만들었을 법한 무언가로 들린다. 수백만 개의 선호 쌍으로 훈련된 모델이 “좋은 음악”이라 여기는 것이 아니라.
방금 무언가가 내 취향을 생성기가 쓸 수 있는 형태로 컴파일했다. 묘사한 것이 아니다. 점수를 매긴 것도 아니다. 컴파일했다. 번역가가 한 언어를 말하면서 익히듯, 주고받을 때마다 번역이 다듬어지고 그 번역은 늘 잠정적인 그런 방식으로. 1부는 이 컴파일러가 주요 생성 시스템마다 빠져 있다고 논했다. 지금의 접근은 취향을 스칼라 보상으로 짓눌러 평평하게 만들고, 인구 집단의 중앙값을 향해 최적화하며, 창작 산출을 아낄 만한 것으로 만드는 개개인의 봉우리를 씻어 낸다. 이 글은 그 컴파일러를 짓는다.
1. Taste Compiler(취향 컴파일러)를 이루는 다섯 발상
이 모델은 다섯 발상 위에 선다. 각 발상은 기존 시스템이 무시하는 취향의 한 성질에 응답한다.
- 취향을 안정된 특질과 변덕스러운 세션 상태로 나눈다
- 맥락에 조건화된 쌍선형 효용으로 후보의 점수를 매긴다
- 선택, 편집, 근거, 거부에서 따로따로 배운다
- 2차 곡률을 자연스러운 정보량 가중치로 삼아 온라인으로 믿음을 갱신한다
- 기대 정보 이득을 최대화해 다음에 보여 줄 것을 고른다
취향에는 안정된 성분과 변덕스러운 성분이 있고, 하나의 학습률로 묻힌 단일 임베딩으로는 영구적 변화와 스쳐 가는 기분을 가를 수 없다. 그래서 첫 수는 분해된 취향 상태 z = z_trait + z_state다. z_trait은 세션을 가로지르며 천천히 갱신되는 안정된 선호를 담고, z_state는 한 세션 안에서 빠르게 갱신되는 지금의 의도를 담는다.
취향 상태는 효용 함수가 사용자가 어떤 상황에 있는지 알아야만 쓸모가 있다. 코딩할 때 배경 음악으로 듣는 취향은 디너 파티 음악의 취향과 다르다. 여기서 맥락 조건화를 명시한 쌍선형 효용이 나온다. u(x) = z⊤ h_φ(x, c, y)이며, 같은 후보 x라도 맥락이 다르면 다른 표현을 낳는다. 취향은 특징 공간 속 하나의 방향이 되고, 맥락은 상황마다 별도의 취향 벡터를 요구하는 대신 표현을 통해 들어온다.
사용자는 그저 고르기만 하지 않는다. 손보고, 설명하고, 거부하며, 신호 종류마다 다른 정보를 실어 나른다. 다중 신호 추론은 피드백 종류마다 별도의 경로를 내준다. 신호 종류에 따라 취향 벡터 z, 그 불확실성, 또는 표현 h_φ를 갱신한다.
선택이라고 다 똑같이 정보가 많은 것도 아니다. 2차 곡률을 쓰는 베이즈 온라인 갱신은 사후 분포가 관측을 정보량에 따라 자연스럽게 가중하도록 한다. 확신에 찬 선택은 큰 헤시안을 낳아 추정을 크게 옮긴다. 미적지근한 선택은 거의 흔적을 남기지 않는다. 사후 공분산은 다음에 무엇을 보여 줄지도 일러 준다.
끝으로, 선택이라는 사건은 후보가 잘 골랐을 때만 정보가 된다. 같은 모드의 변형 여덟 개를 만들어 보여 주면 사용자의 선택은 거의 아무것도 말해 주지 않는다. 정보이론적 포트폴리오 선택은 사용자 취향에 관한 기대 정보 이득을 최대화하는 후보 집합을 구성한다. 이것이 1부에서 진단한 안전한 중앙값으로의 붕괴를 막는다.
이 다섯이 함께 고리를 이룬다. 이 글의 나머지는 각 구성 요소를 낱낱이 규정한다.
2. 전체 파이프라인, 생성에서 학습까지 한 라운드 안에서
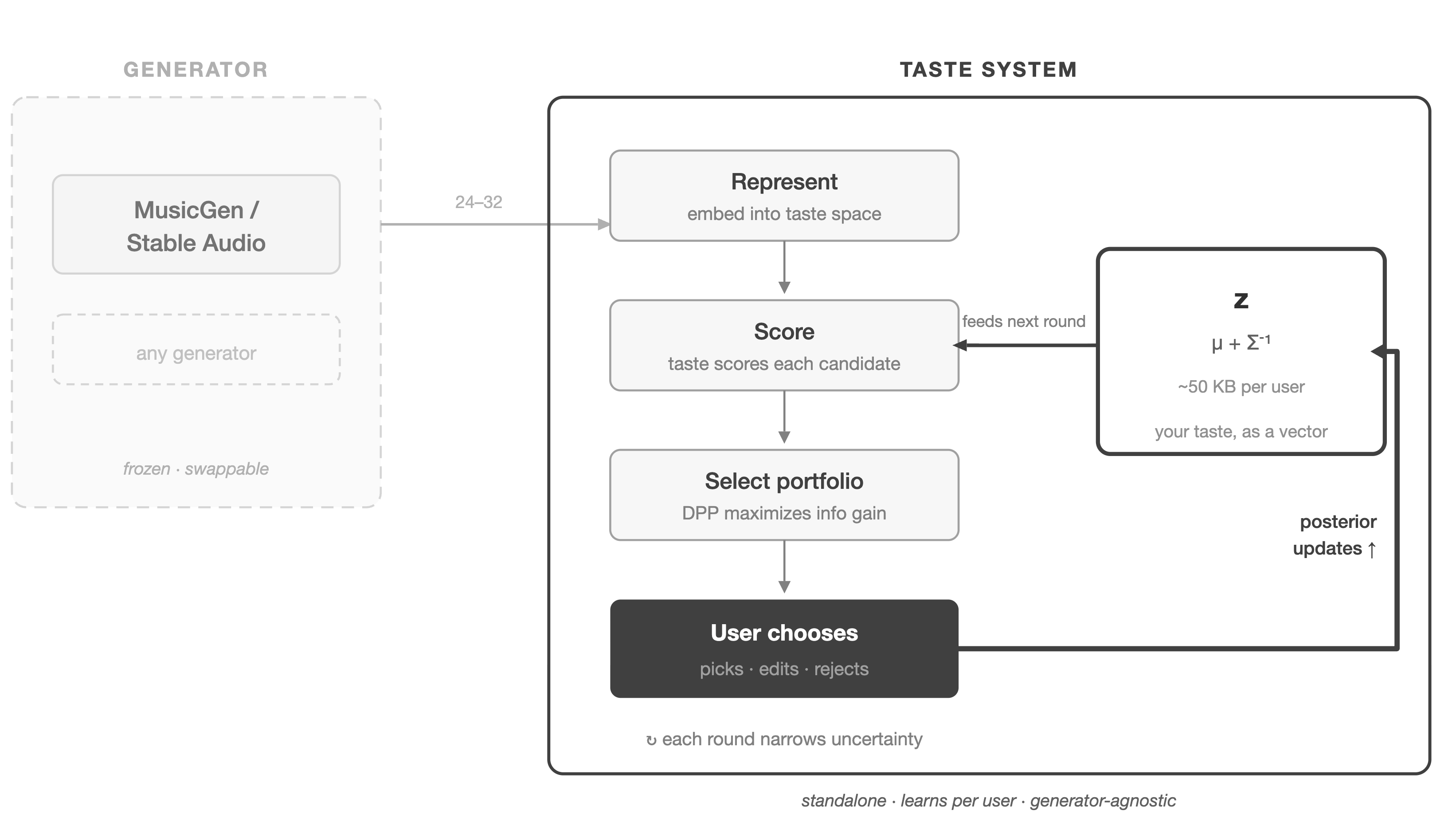
전체 파이프라인은 다음과 같다. 각 구성 요소는 그것이 등장하는 순간에 규정한다.
후보 풀. 고리는 MusicGen(또는 Stable Audio Open)에서 나온 N=24-32개의 후보 클립으로 시작한다. 다양성은 공들여 만들어야 한다. 같은 프롬프트에 시드만 바꾸면 자잘한 확률적 변동밖에 얻지 못하기 때문이다. 풀은 세 가지 변동 원천을 거의 같은 비율로 섞는다. 표면 질감의 다양성을 위한 서로 다른 랜덤 시드, 취향과 관련된 축을 따라 프롬프트를 체계적으로 늘리기(기본 프롬프트에 “sparse arrangement,” “dense layered,” “warm analog,” “bright digital,” “dry close-miked,” “ambient reverb” 같은 스타일 수식어를 덧붙임), 그리고 가이던스 스케일 변동(낮은 스케일은 더 뜻밖의 산출을 내고, 높은 스케일은 프롬프트에 더 가깝게 머문다)이다. 이렇게 하면 프로덕션 스타일, 편곡 밀도, 음색에 걸쳐 진짜 폭이 생긴다.
표현. 각 후보는 h_φ를 거친다. h_φ는 (오디오, 맥락, 프롬프트)를 취향 공간 ℝ^d(d=64)로 옮기는 표현 신경망이다. 왜 64인가. CLAP 임베딩 공간을 투영한 뒤 변동의 주요 축을 담기에 충분히 크면서, 관측이 드문 초기 라운드에서 정밀도 행렬 Σ^{-1}이 잘 조건화된 채로 남을 만큼 작기 때문이다. 얼어붙은 CLAP 오디오 인코더가 512차원 임베딩 e_audio를 낸다. CLAP의 텍스트 인코더는 프롬프트에서 e_text를 낸다. 맥락 c(“focus”나 “social” 같은 범주형 태그, 또는 자유 텍스트 설명)는 학습된 임베딩이나 같은 텍스트 인코더로 부호화되어 e_context를 낸다. 이 세 벡터를 이어 붙여 1536차원 입력으로 만들고 2층 MLP(1536 → 256 → d, ReLU 활성화)에 통과시킨다. MLP가 유일하게 학습되는 구성 요소다. 인코더는 얼어붙은 채로 두어, 사용자별 작은 데이터셋으로도 시스템이 훈련 가능하도록 유지한다.
한 가지 단서. CLAP은 취향에 중요한 프로덕션 차원의 구분(리버브 성격, 스테레오 폭, 컴프레션 스타일)이 아니라 일반 오디오로 훈련되었다. 얼어붙은 인코더는 지각적으로 또렷이 다른 후보들을 가까운 임베딩으로 뭉뚱그릴 수 있다. h_φ MLP가 어느 정도 메울 수 있지만, 이 구성 요소는 더 나은 음악 전용 인코더가 나오면 가장 먼저 교체가 필요할 부분이다.
각 후보의 효용은 쌍선형 형식이다.
u(x) = z⊤ h_φ(x, c, y)
취향 벡터 z는 특징 공간 속 하나의 방향을 정하고(τ와 사전 분포가 정하는 스케일까지), 효용은 각 후보의 표현과의 내적이다. 사전 분포는 z ~ N(0, λ^{-1}I)이며, λ는 효용 크기를 τ에 견주어 O(1)로 유지하도록 고른다. τ는 전역으로 고정하고 ‖z‖는 사전 분포로 규제하여, 선택 온도와 취향 크기 사이의 퇴화를 피한다. 맥락 변화는 맥락별 취향 벡터를 따로 두지 않고 표현이 처리한다.
포트폴리오 선택. 부호화된 후보 N개 중에서 시스템은 보여 줄 K=6-8개를 고른다. 이 선택은 z에 관한 기대 정보 이득을 최대화한다.
I(z; choice | {x_1,…,x_K}) = H[choice | {x_1,…,x_K}] − E_z[H[choice | z, {x_1,…,x_K}]]
부분집합에 걸친 정확한 상호정보 최대화는 조합적이다. 우리는 이를 품질 가중 DPP로 근사한다. 커널은 K_ij = q_i · h_φ(x_i)⊤h_φ(x_j) · q_j이고, q_i = exp(μ_t⊤h_φ(x_i))다. DPP는 특징 공간을 펼치되 효용이 높은 영역으로 치우치게 부분집합을 고른다. 32×32 커널에서의 정확한 표집은 대화형 사용에도 충분히 값싸다. DPP가 고른 후보들 가운데, 시스템은 사후 효용 분산 Var_z[u(x)] = h_φ(x)⊤ Σ_t h_φ(x)가 높은 것, 곧 시스템이 가장 불확실해하는 지점을 앞세운다. 한두 자리는 기대 효용 μ_t⊤h_φ(x)가 높은 후보로 비워 두어, 사용자가 탐험과 함께 수렴도 보게 한다. 초기 라운드(큰 tr(Σ_t))는 다양성을 선호한다. 뒤 라운드는 봉우리 찾기로 옮겨 간다. 단순한 스케줄이 floor(K · min(1, tr(Σ_t)/tr(Σ_0)))개 자리를 탐험에 배정한다. 이는 불확실성 질량의 어림 대용이며, 사후 엔트로피의 어떤 단조 함수든 비슷하게 작동한다.
DPP 커널은 h_φ 공간의 내적이 지각적 유사도에 대응한다고 가정한다. 표현에 사각이 있다면(있을 것이다, 위의 CLAP 단서를 보라) DPP는 임베딩에서는 다양해 보이지만 사용자에게는 비슷하게 들리는 후보를 고를 수 있다. 포트폴리오 안에서 사용자가 느끼는 중복을 살피고 이를 신호로 되먹이는 일은 아직 풀리지 않은 설계 문제다.
“ambient piano” 프롬프트의 1라운드 포트폴리오에는 이런 것이 들 수 있다. 듬성하고 리버브가 짙은 테이크, 마른 근접 마이킹 버전, 빽빽하게 겹쳐 쌓은 편곡, 두 음만의 미니멀한 모티프, 따뜻한 아날로그로 처리한 클립, 그리고 서브베이스가 도드라진 하나. 이 폭에서 사용자가 고른 선택은 후보들이 h_φ 공간에서 멀찍이 떨어져 있어 큰 기울기를 낳는다.
사용자가 응답한다. 사용자는 후보 하나를 고르고, 원한다면 선택을 손보거나 설명하거나, 전부 거부한다. 선택 모델은 다항 로짓이며, 쌍별 비교로 줄이는 대신 K개 전부의 선택 집합을 우도에 그대로 쓴다.
P(pick x_i | z, {x_1,…,x_K}, c, y) = exp(u(x_i) / τ) / Σ_j exp(u(x_j) / τ)
온도 τ는 선택의 날카로움을 조절하며, 응답 시간이나 망설임 패턴 같은 행동 신호에서 사건마다 추론할 수 있다. 빠르고 단호한 선택은 낮은 τ를, 머뭇거리는 선택은 높은 τ를 뜻한다.
사후 분포가 어떻게 갱신되는가. 우리는 z의 사후 분포를 가우시안으로 근사해 두고, 로짓 우도의 기울기와 곡률을 써서 온라인으로 갱신한다. p_j = exp(u(x_j)/τ) / Σ_k exp(u(x_k)/τ)를 예측 선택 확률이라 하고 h_j = h_φ(x_j)를 후보 표현이라 하자. 소프트맥스 로그 우도의 기울기와 헤시안은 닫힌 형식을 갖는다.
∇_z log P(pick x_i | z) = (1/τ)(h_i − Σ_j p_j h_j)
∇²_z log P(pick x_i | z) = −(1/τ²)(Σ_j p_j h_j h_j⊤ − (Σ_j p_j h_j)(Σ_j p_j h_j)⊤)
기울기는 고른 후보의 표현과 확률 가중 평균의 차이, 곧 “놀라움” 방향이다. 헤시안은 표현들의 확률 가중 공분산에 음의 부호를 붙인 것이다. 사후 갱신은 다음과 같다.
μ_{t+1} = μ_t + Σ_t · (1/τ)(h_i − Σ_j p_j h_j)
Σ_{t+1}^{-1} = Σ_t^{-1} + (1/τ²)(Σ_j p_j h_j h_j⊤ − (Σ_j p_j h_j)(Σ_j p_j h_j)⊤)
이것은 d=64에서 라운드마다 한 번의 작은 2차 갱신이며(64×64 정밀도 행렬, 사용자당 대략 50KB), 최적화 루프도 없고 생성기를 거치는 역전파도 없다. 헤시안은 정보의 비대칭을 자동으로 강제한다. 확신에 찬 선택은 큰 헤시안을 낳아 사후 분포를 크게 수축시킨다. 미적지근한 선택은 거의 흔적을 남기지 않는다.
여기에 한 가지 위험이 있다. 보여 준 h 벡터들이 저랭크 부분공간에 머물면(포트폴리오에 진짜 다양성이 없을 때 그렇게 된다) 곡률 갱신이 잘못 조건화된다. 실제로 이는 포트폴리오 선택 단계가 갱신 단계를 떠받치고 있다는 뜻이다. 다양성이 빈약한 포트폴리오는 사용자의 주의를 낭비하는 데 그치지 않는다. 사후 분포를 망가뜨릴 수 있다.
보조 신호. 사용자가 더 풍부한 피드백을 주면 추가 경로가 켜진다.
편집. 사용자가 편집을 말한다(“리버브를 줄여”). 시스템은 편집 지시를 덧붙인 프롬프트에서, 무관한 변동을 줄이려 같은 랜덤 시드로 다시 생성한다. 편집 방향 Δ = h_φ(x_i’) − h_φ(x_i)는 어떤 특징을 따라 움직여야 하는지를 곧장 일러 주는 신호다. 손실 L_edit = −z⊤Δ / (‖z‖ ‖Δ‖)는 z를 그 방향에 맞춰 끌어당긴다. 시드 맞춤이 결정적이다. 그러지 않으면 확률적 재생성 변동이 편집 신호를 묻어 버린다. 생성기가 시드에 확실히 조건화되지 않는다면, 짝지은 변형을 여럿 만들어 Δ를 평균 내어 근사한다. 편집 하나는 통째 후보를 순위 매기는 대신 특정 축을 짚어 내므로, 순수한 선택 두세 라운드만큼의 값어치가 있다.
근거. 텍스트 근거는 텍스트 인코더를 거쳐 임베딩 r로 부호화된다. 대조 손실 L_rationale = −log [exp(sim(h_φ(x_selected), r)) / Σ_j exp(sim(h_φ(x_j), r))]는 h_φ의 특징 공간을 빚어, 사용자들에 걸쳐 점점 더 취향과 관련되게 만든다. MLP는 이 기울기들을 쌓아 밤마다 묶음 단위로 갱신하고, z는 실시간으로 갱신된다.
거부. 전체 거부는 사후 분포를 부풀린다. Σ_{t+1} = Σ_t + σ²_reject · I이며, 다음 라운드는 넓게 탐험해야 한다는 신호다.
세션 간 지속. 한 세션 안에서는 모든 갱신이 z_state를 겨냥한다. 세션을 가로지르면 z_trait이 혼합 규칙을 거쳐 세션의 증거를 흡수한다.
μ_trait ← (1 − α_trait) μ_trait + α_trait · μ̄_state^(session)
Σ_trait^{-1} ← (1 − β_trait) Σ_trait^{-1} + β_trait · Σ̄_state^{-1 (session)}
여기서 α_trait ≈ 0.01-0.05이고 β_trait은 특질 수준의 확실성이 얼마나 빨리 자라는지를 조절한다. z_trait은 사용자당 (μ, Σ^{-1}) 쌍으로 저장된다. 새 세션이 시작될 때마다 z_state는 z_trait에서 초기화되어 거기서부터 적응한다.
지연. 사용자가 지금의 포트폴리오를 살펴보는 동안 시스템은 다음 후보 풀을 미리 생성한다. 사용자가 응답하면 사후 분포가 마이크로초 안에 갱신되고, 포트폴리오 선택이 새 μ와 Σ로 미리 생성된 풀 위에서 다시 돌아가며, 다음 라운드가 체감 대기 시간이 거의 0인 채로 나타난다.
작동하는 고리. 1라운드에서는 Σ_0이 가장 커서 DPP가 지배하고 포트폴리오가 스타일 공간을 펼친다. 멀찍이 떨어진 후보들에서 나온 한 번의 선택은 큰 헤시안을 낳아 사후 분포를 크게 수축시킨다. 3-5라운드쯤이면 포트폴리오는 추정된 봉우리 근처에 모이고, 가장 불확실한 차원을 따라 작은 흔들림을 준다. 편집은 특정 축에서의 수렴을 앞당긴다. 사용자가 굳어진 패턴을 거스르면 z_state가 그 변화를 흡수하고 z_trait은 버틴다. 다음 포트폴리오는 두 방향을 다 좇는 후보로 위험을 분산한다. Σ_t의 주요 차원이 작아지고 나면, 탐험은 직교 부분공간으로 다시 배정되어, 사용자가 아직 살펴보지 않았지만 표현이 좋아할 법하다고 예측하는 후보를 끌어 올린다. 이것은 능동적 발견이며, 보정된 불확실성이 구조화된 표현과 맞물려 떠오른다.
3. 이 시스템이 함의하는 것
생성은 흔해지고 있다. 취향 레이어는 아니다. 주류 프롬프트에서는 MusicGen, Stable Audio, Suno, Udio에 걸쳐 생성 품질이 수렴하고 있다. 취향 고리는 어떤 생성기 위에도 얹히며, 사용자가 실제로 체감하는 부분이다. 생성이 인프라가 되어 갈수록 취향 레이어는 제품 표면이 된다.
취향 데이터는 소비 데이터가 할 수 없는 방식으로 복리로 쌓인다. 추천 시스템은 고정된 카탈로그에서 무엇을 소비했는지로 배운다. 취향 고리는 반사실 선호 데이터를 낳는다. 시스템이 생성하기 전에는 없던 것들 가운데 무엇을 골랐는가다. 이는 어떤 카탈로그에도 없는 영역의 선호를 드러내고, 플라이휠을 돌린다. 사용자가 늘수록 h_φ의 표현이 좋아지고, 그러면 새 사용자의 취향 추론이 빨라진다. 취향 레이어는 생성기와도 분리되어 있어, 사용자의 z_trait이 도구와 양식을 가로질러 옮겨 다닐 수 있다.
취향 축 설계, 바로 거기에 도메인 전문성이 산다. 음악과 이미지에 알맞은 프롬프트 증강 축은 각각 무엇인가. 어떤 지각 차원이 인간의 선호를 가르며, 그것을 ℝ^d로 어떻게 옮겨야 하는가. 정보 이득을 최대화하는 콜드 스타트 온보딩은 어떻게 설계하는가. 이런 물음에는 도메인 전문성과 표현 학습에 능숙함이 함께 녹아야 한다. 이 일은 생성기가 좋아질수록 더 중요해진다. 더 풍부한 산출 공간일수록 더 정교한 항해가 필요하기 때문이다.
가장 중요한 실패 양상은 조용한 표류다. 선호를 잘못 배운 취향 모델은 이후 모든 라운드를 망가뜨린다. z_trait이 잘못 표류하면 포트폴리오를 망치고, 그러면 더 나쁜 선택을 낳고, 그 선택이 다시 표류를 굳힌다. 시스템에는 보정 모니터링, 표류 탐지, 부드러운 회복이 처음부터 설계되어 들어가야 한다.
4. 풀리지 않은 문제와 어디서 시작할까
수렴 속도. z가 무작위 포트폴리오를 앞서기까지 몇 라운드가 걸리는가. 가설은 음악은 3-5라운드(d=64, K=8), 이미지는 5-10라운드다. 라운드 수의 함수로, 따로 떼어 둔 선택의 예측으로 잴 수 있다.
탐험 예산. 위의 탐험-활용 스케줄은 어림짐작이다. 누적 후회에 관한 베이즈 최적화 문헌이 이론적 도구를 주지만, 창작 환경에서의 경험적 물음은 아직 연구되지 않았다.
신호 희소성. 대부분의 사용자는 클릭만 할 것이다. 편집이나 근거가 없을 때의 저하 곡선은 어떤 모양인가. 절제 실험으로 잴 수 있다.
취향 표류. z_trait은 몇 주씩 떨어진 세션을 가로질러 어떻게 갱신해야 하는가. z_state와 z_trait 사이의 KL 발산을 살피다가 발산이 클 때 더 빠른 혼합을 촉발하는 변화점 탐지 레이어가, 단순 감쇠보다 나을지 모른다.
h_φ 콜드 스타트. h_φ의 특징 공간이 취향과 관련된 축에 정렬되기까지 시스템은 사용자를 몇 명이나 보아야 하는가.
내가 가장 먼저 돌려 볼 실험은 MusicGen이나 Stable Audio Open으로 하는 음악 생성이다. 30-50명의 참가자가 5-8세션에 걸쳐, 무작위 포트폴리오와 선택만 쓰는 학습과 다중 신호를 다 쓰는 학습을, 스칼라 RLHF 및 협업 필터링 기준선에 견준다. 핵심 지표는 수렴 속도, 따로 떼어 둔 취향 예측(처음 보는 집합에서의 top-1/top-3), 그리고 승인된 산출물 사이의 다양성이다.
각각 논문 하나만큼의 값어치가 있는 세 문제.
표현 학습. 기준선인 얼어붙은 CLAP 더하기 선형 투영 대 파인튜닝 대 밑바닥부터를, 라운드별 예측 정확도로 잰다. 가설은 파인튜닝이 더 빨리 수렴하고, 그 격차는 1-3라운드에서 가장 크다는 것이다.
스케일링 법칙. 수렴은 d, K, 인구 다양성에 따라 어떻게 변하는가. 정보이론적 논증은 최선의 경우 O(d / log K) 라운드를 시사한다. 이 한계에 견준 경험적 측정은 취향 추론을 율-왜곡 이론에 잇는다.
교차 양식 전이. 음악에서 배운 z가 이미지 선호를 예측하는가. MusicGen과 Stable Diffusion에 걸친 같은 사용자들(Pick-a-Pic나 HPD v2로 평가). 두 z 벡터 사이의 정준 상관 분석.
짓는 이들을 위해. 생성에는 MusicGen, h_φ에는 얼어붙은 CLAP 더하기 2층 MLP, 사건별 τ를 쓰는 소프트맥스, 닫힌 형식 헤시안을 쓰는 온라인 가우시안 갱신, 프롬프트 증강과 시드/가이던스 변동으로 만든 24-32개 후보에서의 DPP 포트폴리오 선택. z_trait은 사용자당 (μ, Σ^{-1})로 저장한다. 사용자가 지금 라운드를 살펴보는 동안 다음 풀을 미리 생성한다. 첫 버전이 보여 줄 것은 하나다. 취향에 조건화된 포트폴리오가 무작위보다 빨리 수렴한다는 것.
내가 내일 이 일을 시작한다면, 고리를 닫는 가장 단순한 버전을 짓겠다. MusicGen, 얼어붙은 CLAP, 소프트맥스 선택, 온라인 가우시안 갱신, DPP 포트폴리오. 편집도, 근거도, 세션 간 지속도 없이. 물음은 하나다. 취향에 조건화된 포트폴리오가 무작위보다 빨리 수렴하는가. 그렇다면 이 글의 나머지는 다 공학이다. 그렇지 않다면 표현이 잘못된 것이고 나머지는 아무것도 중요하지 않다.
이는 음악 너머의 일이다. 이미지 생성기, 영상 생성기, 코드 생성기, 모두 같은 문제로 수렴하고 있다. 산출 품질은 사람이 정작 무엇을 원하는지 말할 수 있는 능력보다 빠르게 나아지고 있다. 생성 쪽에는 수십억의 자금과 수천 명의 연구자가 있다. 취향 쪽에는 거의 아무도 없다. 그 비대칭은 오래가지 않는다. 생성이 흔한 인프라가 되는 순간, 방어 가능한 유일한 레이어는 지금 이 사람에게 무엇을 생성할지 아는 레이어이기 때문이다. 그 레이어를 짓는 이가 창작 스택 전체의 인터페이스를 차지한다.
참고 문헌
Christiano et al. (2017). Deep Reinforcement Learning from Human Preferences. 이 작업이 출발점으로 삼아 갈라져 나온 토대 RLHF 프레임워크.
Luce, R.D. (1959). Individual Choice Behavior: A Theoretical Analysis.
McFadden, D. (1973). Conditional Logit Analysis of Qualitative Choice Behavior.
Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. 선호 정렬의 현 지배적 접근. 우리 시스템은 DPO가 겨냥하지 않는 사용자별, 온라인, 다중 신호 환경을 다룬다.
Elizalde et al. (2023). CLAP: Learning Audio Concepts from Natural Language Supervision. h_φ의 얼어붙은 백본으로 쓰인 오디오-텍스트 인코더.
Kulesza & Taskar (2012). Determinantal Point Processes for Machine Learning.
Kirstain et al. (2023). Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation.
Wu et al. (2023). Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.
Dumoulin et al. (2024). A Density Estimation Perspective on Learning from Pairwise Human Preferences.
Gao et al. (2024). PRELUDE: Aligning LLM Agents by Learning Latent Preference from User Edits. NeurIPS 2024.
Huang et al. (2025). MusicPrefs: A Large-Scale Dataset for Music Preference Prediction.
Tan et al. (2024). Democratizing Large Language Models via Personalized Parameter-Efficient Fine-tuning (One PEFT Per User).
Charakorn et al. (2026). Doc-to-LoRA: Learning to Instantly Internalize Contexts. Sakana AI.