趣味コンパイラ
生成系のためのリアルタイムな趣味推論をどう組み立てるか。
英語の原文から翻訳 · 機械翻訳の下書き、未校閲
Taste Model シリーズの第2部。第1部は、スカラー報酬が峰を均してしまうと論じた。本稿はその代わりとなるものを組み立てる。
音楽生成器にプロンプトを与える。8つのクリップが返ってくる。ほとんどは手堅く、ありふれて聞こえる。私はまばらなピアノの編曲と、抑えの効いたドラムのものを選ぶ。「リバーブを減らして、低域を締めて」と打ち込む。次のバッチが届く。近づいた。また選び、また手を入れる。あと2巡。出てきたものは、もし私に腕があれば自分で作っただろうものに聞こえる。何百万もの選好ペアで訓練されたモデルが「良い音楽」と見なすものではなく。
いま何かが、私の趣味を生成器の使える形へとコンパイルした。記述したのではない。採点したのでもない。コンパイルしたのだ。翻訳者が話すことで言語を学ぶように、やり取りのたびに訳が磨かれ、その訳はつねに暫定的である、というふうに。第1部は、この Taste Compiler(趣味コンパイラ)がどの主要な生成系にも欠けていること、現在の手法は趣味をスカラー報酬へと均し、母集団の中央値へ向けて最適化し、創作物を気にかける値打ちあるものにしているはずの個々の峰を洗い流してしまうこと、を論じた。本稿はそのコンパイラを組み立てる。
趣味コンパイラをなす5つの発想
このモデルは5つの発想に立つ。それぞれが、既存のシステムが見落としている趣味の性質に応じている。
- 趣味を、安定した特性と移ろう局面状態とに分ける
- 候補を、文脈で条件づけた双線形効用で採点する
- 選択、編集、根拠、棄却から、それぞれ別々に学ぶ
- 二次の曲率を自然な情報量の重みとして用い、信念をオンラインで更新する
- 次に何を見せるかを、期待情報利得を最大化するように選ぶ
趣味には安定した成分と移ろう成分があり、一つの学習率に置いた一つの埋め込みでは、永続的な変化と過ぎゆく気分とを区別できない。そこで最初の一手は decomposed taste state(分解された趣味状態) z = z_trait + z_state である。z_trait は安定した選好をとらえ、セッションをまたいでゆっくり更新される。z_state は当面の意図をとらえ、セッションの内側で速く更新される。
趣味状態が役に立つのは、効用関数がユーザーの置かれた状況を知っているときだけだ。コーディングの背景に流す音楽の趣味は、ディナーパーティーの音楽の趣味とは違う。ここから bilinear utility with explicit context conditioning(文脈を明示的に条件づけた双線形効用) が要請される。u(x) = z⊤ h_φ(x, c, y) であり、同じ候補 x も、文脈が違えば違う表現を生む。趣味は特徴空間における一つの方向となり、文脈は、状況ごとに別の趣味ベクトルを要するのではなく、表現を通じて入ってくる。
ユーザーは選ぶだけではない。手を入れ、説明し、棄却する。そして信号の種類ごとに運ぶ情報は違う。multi-signal inference(複数信号推論) は、フィードバックの種類ごとに別の経路を与え、信号の種類に応じて趣味ベクトル z、その不確実性、あるいは表現 h_φ を更新する。
選択がどれも等しく情報を持つわけでもない。二次の曲率を用いたベイズ的オンライン更新 によって、事後分布は観測をその情報量で自然に重みづけできる。確信のある選択は大きなヘッセ行列を生み、推定を大きく動かす。気乗りのしない選択はほとんど刻まれない。事後共分散はまた、次に何を見せるべきかをシステムに教える。
最後に、選択という出来事が情報を持つのは、候補がよく選ばれていたときに限る。同じモードのバリエーションを8つ生成すれば、ユーザーの選択はほとんど何も語らない。情報理論的なポートフォリオ選択 は、ユーザーの趣味についての期待情報利得を最大化する候補集合を組む。これが、第1部の診断した安全な中央値への崩落を防ぐ。
これらが合わさって一つのループをなす。本稿の残りは、各構成要素を一つずつ規定していく。
全体のパイプライン、生成から学習まで一巡で
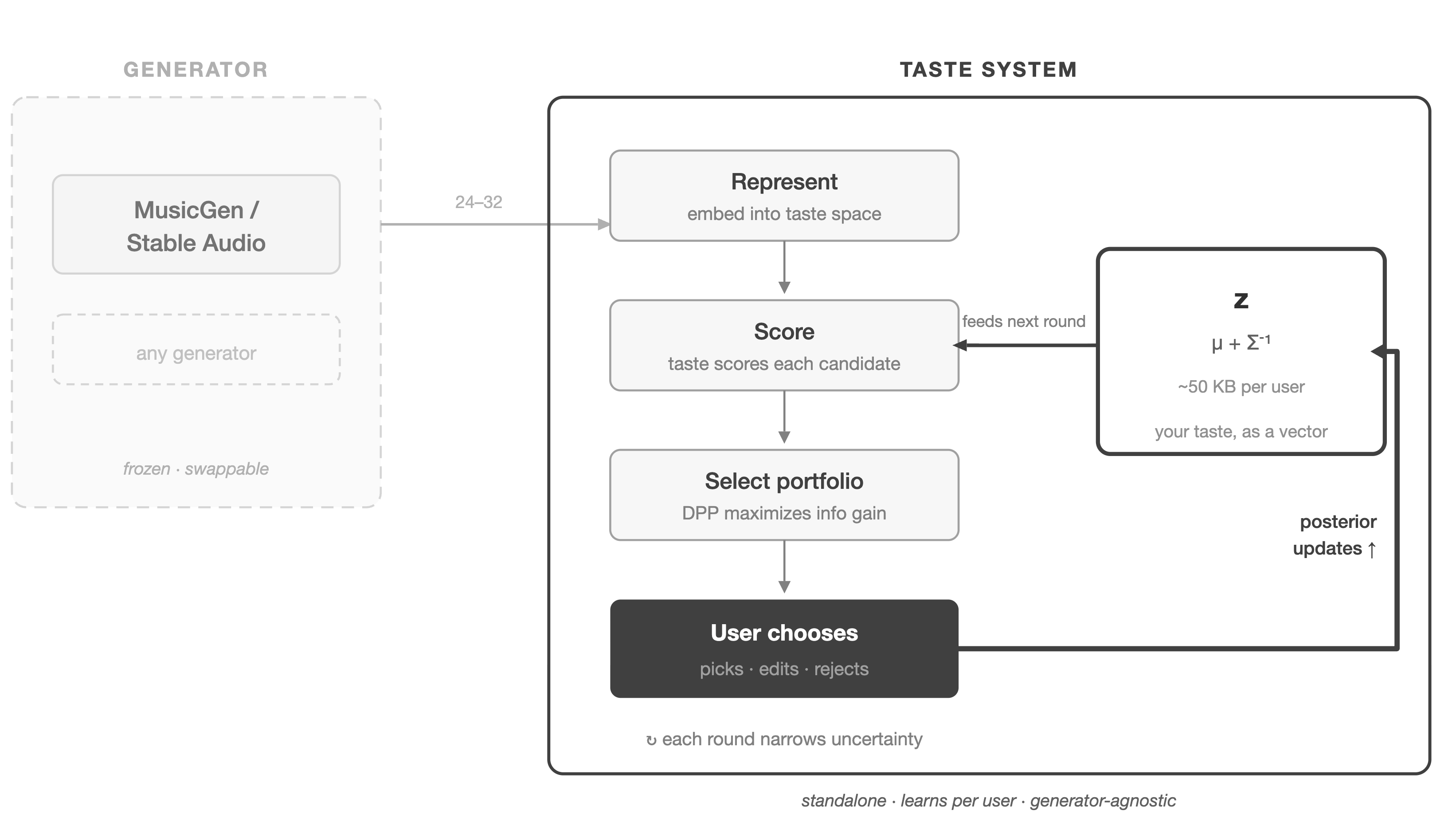
これが全体のパイプラインである。各構成要素を、それが入ってくる地点で規定していく。
候補プール。 ループは、MusicGen(あるいは Stable Audio Open)からの N=24-32 個の候補クリップで始まる。多様性は設計して作り込まねばならない。同じプロンプトでも、乱数シードを変えるだけではわずかな確率的ばらつきしか得られないからだ。プールは三つのばらつき源を、おおよそ等しい割合で組み合わせる。表層の質感を多様にするための異なる乱数シード、趣味に関わる軸に沿った系統的なプロンプト拡張(基本プロンプトに「sparse arrangement」「dense layered」「warm analog」「bright digital」「dry close-miked」「ambient reverb」といったスタイル修飾語を付け足す)、そしてガイダンススケールの変化(低いスケールはより意外な出力を生み、高いスケールはプロンプトの近くにとどまる)である。これにより、プロダクションのスタイル、編曲の密度、音色の性格にわたって、本物の広がりが生まれる。
表現。 各候補は h_φ、すなわち(音声、文脈、プロンプト)を趣味空間 ℝ^d(d=64)へ写す表現ネットワークを通る。なぜ64か。射影後の CLAP 埋め込み空間における変化の主要な軸をとらえるには十分大きく、観測がまばらな初期の巡で精度行列 Σ^{-1} が良条件にとどまる程度には十分小さいからだ。凍結した CLAP 音声エンコーダが512次元の埋め込み e_audio を生む。CLAP のテキストエンコーダがプロンプトから e_text を生む。文脈 c(「focus」や「social」のようなカテゴリのタグ、あるいは自由記述)は、学習された埋め込みか同じテキストエンコーダで符号化され、e_context を生む。この三つのベクトルが連結されて1536次元の入力となり、二層の MLP(1536 → 256 → d、ReLU 活性)を通る。MLP が唯一の学習される構成要素である。エンコーダは凍結したままで、ユーザーごとの小さなデータセットでもシステムを訓練可能に保つ。
ただし留保が一つ。CLAP は一般の音声で訓練されており、趣味にとって意味を持つプロダクション水準の区別(リバーブの性格、ステレオ幅、コンプレッションのスタイル)で訓練されたわけではない。凍結したエンコーダは、知覚的に異なる候補を近接した埋め込みへ潰してしまうかもしれない。h_φ の MLP はこれを部分的には補えるが、ここは、より音楽に特化したエンコーダが現れたときに、最も差し替えを要しそうな構成要素である。
各候補の効用は双線形の形をとる。
u(x) = z⊤ h_φ(x, c, y)
趣味ベクトル z は特徴空間における一つの方向を定め(スケールは τ と事前分布が決める)、効用は各候補の表現との内積である。事前分布は z ~ N(0, λ^{-1}I) で、λ は効用の大きさを τ に対して O(1) に保つように選ぶ。τ は大域的に固定し、‖z‖ を事前分布で正則化することで、選択温度と趣味の大きさのあいだの縮退を避ける。文脈による変化は、文脈ごとに別の趣味ベクトルを置くのではなく、表現が引き受ける。
ポートフォリオ選択。 N 個の符号化された候補から、システムは提示する K=6-8 個を選ぶ。この選択は z についての期待情報利得を最大化する。
I(z; choice | {x_1,…,x_K}) = H[choice | {x_1,…,x_K}] − E_z[H[choice | z, {x_1,…,x_K}]]
部分集合にわたる厳密な相互情報量の最大化は組合せ的だ。これを、品質で重みづけた DPP で近似する。カーネルは K_ij = q_i · h_φ(x_i)⊤h_φ(x_j) · q_j、ここで q_i = exp(μ_t⊤h_φ(x_i)) である。DPP は特徴空間を張る部分集合を選びつつ、高効用の領域へ寄せる。32×32 のカーネルからの厳密なサンプリングは、対話的な利用に十分安い。DPP が選んだ候補のうち、システムは事後効用分散 Var_z[u(x)] = h_φ(x)⊤ Σ_t h_φ(x) の高いもの、すなわちシステムが最も確信を持てない点を優先する。一つか二つの枠は高い期待効用 μ_t⊤h_φ(x) のために確保し、ユーザーが探索と並んで収束も目にできるようにする。初期の巡(tr(Σ_t) が大きい)は多様性を好む。後の巡は峰を探る方へ移る。単純なスケジュールが floor(K · min(1, tr(Σ_t)/tr(Σ_0))) 個の枠を探索に割り当てる。これは不確実性の質量に対する経験則的な代理であり、事後エントロピーの任意の単調関数でも同様に働く。
DPP カーネルは、h_φ 空間における内積が知覚的な類似に対応すると仮定する。表現に盲点があれば(上の CLAP の留保のとおり、必ずある)、DPP は、埋め込みでは多様に見えてユーザーには似て聞こえる候補を選びうる。ポートフォリオにおいてユーザーの感じる冗長さを監視し、それを信号として戻すことは、未解決の設計問題である。
「ambient piano」というプロンプトに対する第1巡のポートフォリオは、たとえば次を含むかもしれない。まばらでリバーブの強いテイク、乾いた近接マイクの版、密に重ねた編曲、最小の二音モチーフ、温かいアナログ処理のクリップ、そして際立つサブベースのもの。この広がりからのユーザーの選択は、候補が h_φ 空間で互いに遠く離れているため、大きな勾配を生む。
ユーザーが応える。 ユーザーは一つの候補を選び、任意でその選択に手を入れるか説明し、あるいはすべてを棄却する。選択モデルは多項ロジットで、ペアごとの比較に還元するのではなく、尤度の中で K 通りの選択集合をまるごと用いる。
P(pick x_i | z, {x_1,…,x_K}, c, y) = exp(u(x_i) / τ) / Σ_j exp(u(x_j) / τ)
温度 τ は選択の鋭さを制御し、応答時間や熟考のパターンといった行動信号から、出来事ごとに推定できる。速く決然とした選択は低い τ を、ためらいがちな選択は高い τ を含意する。
事後分布がどう更新されるか。 z についての事後分布をガウス近似で保ち、ロジット尤度の勾配と曲率を用いてオンラインで更新する。p_j = exp(u(x_j)/τ) / Σ_k exp(u(x_k)/τ) を予測選択確率、h_j = h_φ(x_j) を候補の表現とする。ソフトマックス対数尤度の勾配とヘッセ行列は閉じた形を持つ。
∇_z log P(pick x_i | z) = (1/τ)(h_i − Σ_j p_j h_j)
∇²_z log P(pick x_i | z) = −(1/τ²)(Σ_j p_j h_j h_j⊤ − (Σ_j p_j h_j)(Σ_j p_j h_j)⊤)
勾配は、選ばれた候補の表現と、確率で重みづけた平均との差、すなわち「意外さ」の方向である。ヘッセ行列は、表現の確率で重みづけた共分散の符号を反転したものだ。事後更新は次のとおり。
μ_{t+1} = μ_t + Σ_t · (1/τ)(h_i − Σ_j p_j h_j)
Σ_{t+1}^{-1} = Σ_t^{-1} + (1/τ²)(Σ_j p_j h_j h_j⊤ − (Σ_j p_j h_j)(Σ_j p_j h_j)⊤)
これは d=64 における巡ごとの小さな二次更新であり(64×64 の精度行列、ユーザーあたりおよそ50KB)、最適化ループも、生成器への逆伝播もない。ヘッセ行列が情報の非対称性を自動的に課す。確信のある選択は大きなヘッセ行列を生み、事後分布を大きく収縮させる。気乗りのしない選択はほとんど刻まれない。
ここに一つのリスクがある。提示された h ベクトルが低ランクの部分空間に収まると(ポートフォリオに本物の多様性が欠けるとき、これは起こる)、曲率更新は悪条件になる。実際には、これはポートフォリオ選択の段が更新の段にとって要であることを意味する。多様性に乏しいポートフォリオは、ユーザーの注意を無駄にするだけではない。事後分布を損ないうる。
補助信号。 ユーザーがより豊かなフィードバックを与えれば、追加の経路が働きだす。
編集。 ユーザーが編集を言葉で示す(「リバーブを減らして」)。システムは、編集の指示を付け足した修正プロンプトから再生成する。無関係なばらつきを最小化するため、同じ乱数シードを用いる。編集方向 Δ = h_φ(x_i’) − h_φ(x_i) は、どの特徴に沿って動くべきかについての直接の信号だ。損失 L_edit = −z⊤Δ / (‖z‖ ‖Δ‖) は、z をその方向へ揃えるよう引っぱる。シードを合わせることは決定的である。それなしには、確率的な再生成のばらつきが編集信号をかき消す。生成器が確実にはシードで条件づかない場合、複数の対になるバリアントを生成して Δ を平均することで近似する。一度の編集は、丸ごとの候補を順位づけるのではなく特定の軸を同定するため、純粋な選択のおよそ2〜3巡分の値打ちがある。
根拠。 テキストの根拠は、テキストエンコーダによって埋め込み r へ符号化される。対照損失 L_rationale = −log [exp(sim(h_φ(x_selected), r)) / Σ_j exp(sim(h_φ(x_j), r))] が h_φ の特徴空間を形づくり、ユーザーをまたいでそれをますます趣味に関わるものにしていく。MLP はこれらの勾配を溜め、夜間のバッチ日程で更新される一方、z はリアルタイムで更新される。
棄却。 全棄却は事後分布を膨らませる。Σ_{t+1} = Σ_t + σ²_reject · I であり、次の巡は広く探索すべきだという合図になる。
セッションをまたぐ永続化。 セッションの内側では、あらゆる更新は z_state を対象とする。セッションをまたぐと、z_trait が混合則を通じてそのセッションの証拠を吸収する。
μ_trait ← (1 − α_trait) μ_trait + α_trait · μ̄_state^(session)
Σ_trait^{-1} ← (1 − β_trait) Σ_trait^{-1} + β_trait · Σ̄_state^{-1 (session)}
ここで α_trait ≈ 0.01-0.05 であり、β_trait は特性水準の確信がどれほど速く育つかを制御する。z_trait はユーザーごとに (μ, Σ^{-1}) の対として保存される。新しいセッションの始めに、z_state は z_trait から初期化され、そこから適応していく。
遅延。 ユーザーが現在のポートフォリオを吟味しているあいだに、システムは次の候補プールを先んじて生成する。ユーザーが応えると、事後分布はマイクロ秒で更新され、ポートフォリオ選択は新しい μ と Σ で先生成済みのプールに対して再実行され、次の巡が、体感ほぼゼロの待ち時間で現れる。
ループの実際。 第1巡では、最大の Σ_0 ゆえに DPP が支配し、ポートフォリオはスタイル空間を張る。遠く離れた候補からの一度の選択が大きなヘッセ行列を生み、事後分布を大きく収縮させる。第3〜5巡までに、ポートフォリオは推定された峰の近くに集まり、最も不確実な次元に沿った摂動を伴う。編集は特定の軸での収束を速める。ユーザーが自分の確立したパターンに反すれば、z_trait が保たれるあいだに z_state がその変化を吸収する。次のポートフォリオは、両方向を追う候補で保険をかける。Σ_t の主要な次元がいったん小さくなると、探索は直交する部分空間へ再配分され、ユーザーがまだ探っていないが表現が好みそうだと予測する候補を浮かび上がらせる。これは予見的な発見であり、較正された不確実性が構造化された表現と相互作用することから立ち現れる。
このシステムが含意するもの
生成はコモディティ化しつつある。趣味のレイヤーはそうではない。 主流のプロンプトでは、生成の品質は MusicGen、Stable Audio、Suno、Udio のあいだで収束しつつある。趣味のループはどの生成器の上にも乗り、ユーザーが実際に感じ取るのはその部分だ。生成がインフラになるにつれ、趣味のレイヤーがプロダクトの表面になる。
趣味データは、消費データには真似のできない仕方で複利的に積み上がる。 推薦システムは、固定されたカタログの中からあなたが何を消費したかから学ぶ。趣味のループは反実仮想の選好データを生む。システムが生成するまで存在しなかったものたちの中から、あなたが何を選んだか、である。これは、どのカタログも含まない領域での選好を明かし、はずみ車を回す。ユーザーが増えれば h_φ の表現が良くなり、それが新しいユーザーの趣味推論を速める。趣味のレイヤーは生成器から切り離せもするので、あるユーザーの z_trait は、ツールやモダリティをまたいで移動しうる。
趣味の軸の設計こそ、領域の専門知が宿る場所である。 音楽に対して、画像に対して、正しいプロンプト拡張の軸とは何か。どの知覚次元が人間の選好を分けるのか、そしてそれをどう ℝ^d へ写すべきか。情報利得を最大化するコールドスタートのオンボーディングをどう設計するか。これらの問いは、領域の専門知と表現学習への習熟との融合を要する。この仕事は、生成器が良くなるほど重みを増す。より豊かな出力空間は、より洗練された航行を要するからだ。
最も重大な失敗様態は、静かなドリフトである。 選好を学び損ねた趣味モデルは、以後のすべての巡を劣化させる。z_trait が誤った方へドリフトすればポートフォリオを毒し、それが悪い選択を生み、それがドリフトを強める。システムには、較正の監視、ドリフトの検出、そして優雅な回復が、最初から設計に組み込まれている必要がある。
未解決の問題と、どこから始めるか
収束の速さ。 z がランダムなポートフォリオを上回るまで何巡か。仮説、音楽では3〜5巡(d=64, K=8)、画像では5〜10巡。巡数の関数としての保留集合上の選択予測で測れる。
探索の予算。 上の探索と活用のスケジュールは経験則だ。累積後悔についてのベイズ最適化の文献は理論的な道具を与えるが、創作的な場面での経験的な問いは未研究である。
信号のまばらさ。 ほとんどのユーザーはクリックするだけだろう。編集も根拠もないときの劣化曲線はどうなるか。アブレーションで測れる。
趣味のドリフト。 数週間隔てたセッションをまたいで、z_trait はどう更新されるべきか。z_state と z_trait のあいだの KL ダイバージェンスを監視し、ダイバージェンスが高いときに混合を速めるよう引き金を引く変化点検出のレイヤーは、単純な減衰を上回るかもしれない。
h_φ のコールドスタート。 h_φ の特徴空間が趣味に関わる軸と揃うまでに、システムは何人のユーザーを見ねばならないか。
私が最初に走らせる実験は、MusicGen か Stable Audio Open を用いた音楽生成で、5〜8セッションにわたる30〜50人の参加者を集め、ランダムなポートフォリオ、選択のみの学習、そして完全な複数信号学習を、スカラー RLHF と協調フィルタリングのベースラインと比べるものだ。鍵となる指標は、収束の速さ、保留した趣味の予測(未見の集合での top-1/top-3)、そして承認された出力どうしの多様性である。
それぞれが一本の論文に値する三つの問題。
表現学習。 ベースラインとしての凍結 CLAP プラス線形射影と、ファインチューニング、ゼロからの学習との比較を、巡ごとの予測精度で測る。仮説、ファインチューニングがより速く収束し、差は第1〜3巡で最大になる。
スケーリング則。 収束は d、K、母集団の多様性とともにどうスケールするか。情報理論的な議論は、最良の場合に O(d / log K) 巡を示唆する。経験的な測定とこの限界との比較は、趣味推論をレート歪み理論へとつなぐ。
モダリティをまたぐ転移。 音楽から学んだ z は画像の選好を予測するか。MusicGen と Stable Diffusion をまたぐ同じユーザー(Pick-a-Pic あるいは HPD v2 に対して評価)。二つの z ベクトルのあいだの正準相関分析。
作り手へ。 生成には MusicGen、h_φ には凍結 CLAP プラス二層 MLP、出来事ごとの τ を伴うソフトマックス、閉じた形のヘッセ行列を伴うオンラインのガウス更新、プロンプト拡張とシード/ガイダンスの変化による24〜32候補からの DPP ポートフォリオ選択。z_trait はユーザーごとに (μ, Σ^{-1}) として保存する。ユーザーが現在の巡を吟味しているあいだに、次のプールを先んじて生成する。最初の版が示すべきはただ一つ、趣味で条件づけたポートフォリオがランダムより速く収束する、ということだ。
もし私が明日これを始めるなら、ループを閉じる最も単純な版を作る。MusicGen、凍結 CLAP、ソフトマックスの選択、オンラインのガウス更新、DPP ポートフォリオ。編集なし、根拠なし、セッションをまたぐ永続化なし。問いは一つ。趣味で条件づけたポートフォリオは、ランダムなものより速く収束するか。もし速ければ、本稿の残りはすべてエンジニアリングである。もし速くなければ、表現が間違っており、ほかの何も意味を持たない。
これは音楽にとどまらない。画像生成器、動画生成器、コード生成器、どれもが同じ問題へ収束しつつある。出力の品質は、自分が本当に何を望むかを言葉にする能力よりも速く向上している。生成の側には数十億の資金と数千の研究者がいる。趣味の側には、ほとんど誰もいない。その非対称は続かない。生成がコモディティのインフラになった瞬間、唯一守りうるレイヤーは、いま、この人に 何を生成すべきかを知っているレイヤーだからだ。そのレイヤーを作る者が、創作スタック全体への入口を握る。
参考文献
Christiano et al. (2017). Deep Reinforcement Learning from Human Preferences. 本研究が出発点として離れていく、RLHF の基礎をなす枠組み。
Luce, R.D. (1959). Individual Choice Behavior: A Theoretical Analysis.
McFadden, D. (1973). Conditional Logit Analysis of Qualitative Choice Behavior.
Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. 選好アラインメントへの、現在の支配的な手法。本システムは、DPO が狙わないユーザーごと・オンライン・複数信号の設定を扱う。
Elizalde et al. (2023). CLAP: Learning Audio Concepts from Natural Language Supervision. h_φ の凍結バックボーンとして用いた音声・テキストエンコーダ。
Kulesza & Taskar (2012). Determinantal Point Processes for Machine Learning.
Kirstain et al. (2023). Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation.
Wu et al. (2023). Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis.
Dumoulin et al. (2024). A Density Estimation Perspective on Learning from Pairwise Human Preferences.
Gao et al. (2024). PRELUDE: Aligning LLM Agents by Learning Latent Preference from User Edits. NeurIPS 2024.
Huang et al. (2025). MusicPrefs: A Large-Scale Dataset for Music Preference Prediction.
Tan et al. (2024). Democratizing Large Language Models via Personalized Parameter-Efficient Fine-tuning (One PEFT Per User).
Charakorn et al. (2026). Doc-to-LoRA: Learning to Instantly Internalize Contexts. Sakana AI.