発見の構造
アルファ碁が思考について明かしたもの
英語の原文から翻訳 · 機械翻訳の下書き、未校閲
ボルヘスは、ありうるすべての本を収めた図書館を想像した。我々はそれを建てた。大規模言語モデルはいまや、語のほぼあらゆる並びを、求めに応じて生成し取り出せる。完璧な司書が到来したのである。
それでも発見は自動化されていない。テキストを生成する費用はゼロに近づいた。本物の洞察の費用は、そうではない。もしすべての答えがすでに「そこにある」のなら、なぜそれをただ調べて引けないのか。
発見は検索ではないからだ。それは航行である。あなたは無限に枝分かれする木の一つの節に立っている。どの選択も、また別の無限を開く。必要とする洞察への道筋を調べて引くことはできない。その洞察の番地そのものが、飛ばすことのできない計算の出力だからだ。いったん見つかった答えを確かめるのはたやすい。それを見つけるのが難しいのである。
2012年、私はまさにこの種の構造を航行するためのモデルを発表した。深さも幅も限りのない無限の木で、有用な信号はどの単一の経路に沿ってあるのでもなく、階層の全体に散らばっている。¹ そのモデルの核心は、各節で最も有望な枝へ注意を集める信号に導かれた再帰的な探索が、無限を扱えるものに変えうるという点にあった。私はテキストコーパスの中の主題の階層をモデル化していた。自分が同じ問題の一つの版に取り組んでいるとは気づいていなかった。
その四年後、あるシステムがその構造を碁盤の上で実証した。
第37手が知っていたこと
十年前の今日、世界王者イ・セドルとの五番勝負の第二局で、アルファ碁(AlphaGo)は五線目に石を置いた。解説者は黙り込んだ。アルファ碁を何か月も研究してきたプロ棋士のファン・フイは、言葉を失った。アルファ碁自身の方策ネットワークは、人間がその手を打つ確率を一万分の一と見積もっていた。
それは美しかった。それは勝ちにつながる手だった。そしてそれは本当に新しかった。
これは検索ではなかった。16万局の人間の対局から得た3000万の局面で訓練された方策ネットワークは、第37手をありそうにないと評価した。アルファ碁が人間の打ち碁についての圧縮された知識だけに頼っていたなら、その手は検討すらされなかっただろう。それは力ずくの探索でもなかった。囲碁にはおよそ10^170通りの盤面がある。答えへ探索しきることはできない。
それは三つの認知操作が協働して生まれたものだった。
**予測。**方策ネットワーク。16万局を超える人間の対局を、次の手についての確率分布へと圧縮したもの。この局面なら、強い棋士は何を打つか。それはおよそ250の合法手を、もっともらしい5手か10手へ絞り込む。これは学習されたパターン認識である。それが告げるのは何がありそうかであって、何が良いかではない。そしてその違いが、途方もなく重要であることが判明する。
**趣味。**価値ネットワーク。盤面を一つ見て、ただ一つの数を出力する。この局面はどれほど良いか。それはどの手を打つべきかを告げない。いまいる場所をどう感じればよいかを告げる。計算を完結させぬまま、中間の状態に方向づけられた価値を割り当てるのである。
**探索。**モンテカルロ木探索 (Monte Carlo Tree Search)。代替手の、入念で逐次的な探索であり、予測(どの枝を探るか)と趣味(どの局面を価値づけるか)に導かれる。一手につき数千の、導かれたシミュレーション。思考のうち、仕事のように感じられる部分だ。
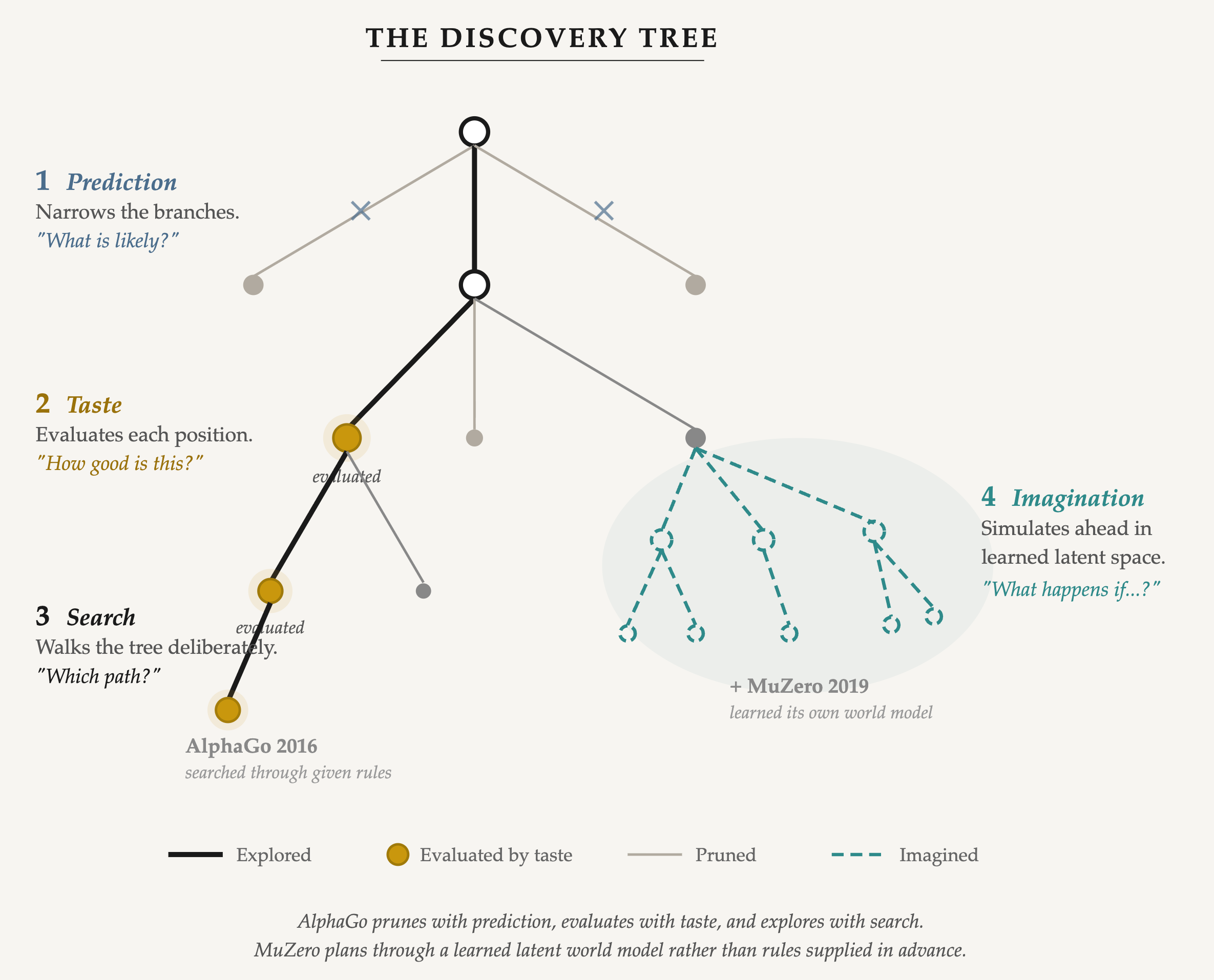
第37手は、その三つの交差点で起きた。予測はそれをありそうにないと評価した。探索はそれでもそれを探った。趣味はその質を見抜いた。発見には三つすべてが要った。
そして同じ勝負の第四局で、イ・セドルは第78手を打った。同じく起こりがたい手。後に「神の一手」として知られることになる。機械の創造性に追い詰められた一人の人間が、自らの訓練分布を超え出たのである。彼はいまなお、正式な対局でアルファ碁に勝った唯一の人間である。彼はその三年後、AIは「打ち負かせない」と語り、プロ棋士を引退した。この構造は機械にも人間にも固有のものではない。発見が広大な空間を導かれて探索することに依るところでは、どこにでも現れる。
その勝負の数年後、アルファ碁の後継であるMuZeroが、何か根本的なものを変えた。アルファ碁は、我々が与えた世界モデル、すなわち囲碁の明示的な規則を通して探索していた。MuZeroはそれを学習した。
**想像。**学習された力学モデルであり、ゲームの規則を一度も与えられぬまま、圧縮された表現の中で未来の状態をシミュレートする。システムは、人間には読めない形をもたない潜在空間の中で、前へと夢を見る。帰結が言語になる前にそれが演じられる、言葉以前の作業空間である。これが構造を内生的にする。システムはもはや、我々が供する世界モデルを通してのみ計画するのではない。計画に必要なモデルを自ら学ぶ。それが、外部の世界モデルの上での探索と、学習された潜在的なモデルを通した計画との違いである。
証明システムと発見システム
現在の大規模言語モデルが供するのは、私が証明システムと呼ぶものである。予測(基盤モデルがパターン照合で行う次トークンの生成)に、探索(o3やDeepSeek R1に組み込まれた思考連鎖の推論)を加えたもの。この二つの操作は、既知の道を仕上げることにかけては強力だ。証明、説明、実装、分析。証明システムはその熟慮をトークン空間を通して外へ出す。各段階は直列で、言葉に展開され、監査できる。その記録を読めるのである。
DeepSeek R1は、純粋な結果のフィードバックから思考連鎖の推論を育て、過程報酬モデルもなく、木探索もなく、自らの誤りを捕まえることを自発的に学ぶ。目を見張る。だがその推論はことごとく自然言語の中で展開される。このモデルには、整合しない断片をまとまるまで宙づりにしておく頑健な仕組みがない。
欠けているのは発見システムである。趣味(言語化を経ずに枝を刈り導く評価の判断)に、想像(言語の隘路を一度も通らぬ圧縮された表現の中での帰結のシミュレーション)を加えたもの。以前のある文章で、私は発見が第三の認知の様式で営まれると論じた。システム2のように遅い(時間と労力を要する)が、システム1のように静かである(言葉の連鎖ではなく潜在的な表現の上で営まれる)。この四エンジンモデルは、その論を厳密にする。証明システムは予測と探索であり、言語を通して外へ出される。発見システムは潜在的な評価と潜在的なシミュレーションに、より重く依る。言葉へはわずかにしか投影されない。
ポアンカレは1908年、この区別を驚くほどの精度で描き出した。彼の数学的創造の四つの段階は、準備、孵化、照明、検証である。ここで最も重要なのは孵化の段階だ。ポアンカレは、着想が「群れをなして」立ち上がり、「いくつかの対がかみ合うまで」ぶつかり合い、それがすべて意識の手前で起こると述べた。それが想像の働く姿である。続く照明、つまり心が「調和的で、したがって一挙に有用かつ美しい或るものたちだけ」を浮かび上がらせる瞬間は、趣味の発火である。残る二つの段階、準備と検証は、そのまま予測と探索に対応する。
MITのシーモア・パパートは、決定的な構造の原理を見抜いた。「意識と無意識という心に加えての第三の行為者」であり、フロイト的な検閲官にいくらか似て、「無意識のパターンの移ろう万華鏡を走査し、その美的な基準を満たすものだけを通す役目を負う」ものである。その第三の行為者が趣味だ。価値ネットワーク。生成の過程にかけられた濾過器。それはまさにアルファ碁の構造(予測が候補を生み、趣味がそれを濾す)であり、そして後に見るとおり、それ以来本物の発見を成し遂げたあらゆるシステムの構造そのものである。
含意は厳しい。AIが発見しうるものの最前線は、評価の信号が尽きる場所のどこであれ、そこにある。
これら四つのエンジンの上流には、モデルが十分には捉えきれない或る操作が横たわる。いかなる評価も可能になる前に、何が存在すべきかを生成すること。問題を見つけること、問いを立てること、仕様がまだ存在しないうちに仕様を書くこと。四つのエンジンが司るのは、探索の対象がいったん存在してからのことだ。だが趣味は、その生成という行為の下流にあるすべてを縛る制約であり、しかも我々が工学的に挑む術を知っている制約なのである。
趣味というボトルネック
趣味がなければ、あなたはバベルの図書館で迷子になる。すべてに手が届くのに、何一つ見つけられない。これは、大規模言語モデルで何かを作っている人々のほとんどが、まだ十分には飲み込んでいない点だ。価値ネットワークこそが、アルファ碁の数千のシミュレーションを、10^170の状態空間を航行するのに足るものにしている。それを取り除けば、同じシミュレーションがさまよう。
2023年の思考の木(Tree-of-Thought)の結果は、これを言語において示した。思考連鎖のプロンプトを用いたGPT-4は、Game of 24の課題の4%を解いた。同じモデルが、自己評価に導かれた木構造の探索を用いると、74%を解いた。同じモデル。同じ知識。違いは、原始的な趣味に導かれた探索だった。粗い趣味であってさえ、扱えない探索を扱える探索へと変える。
過程報酬モデル (Process Reward Model) は、言語のための趣味を作ろうとする有力な試みの一つだ。それは確かめる費用が安いところで働く。数学には確かめられる答えがあり、コードには実行できるテストがある。確かめるのに計算の全体が要るところ、「良い」が文脈と経験とシミュレートしえない帰結に依るところでは、それは失敗する。
技術的な障害は本物だ。2025年のある論文は、選好に基づく訓練が、思考を効果的にするまさにその探索的な推論、すなわち後戻り、自己修正、雑然としつつ実りある探索を、体系的に罰してしまうと論じた。選好のデータはただ雑音まじりなのではない。体系的に誤りでありうる。そして報酬ハッキングがこの問題を増幅する。RLHFはモデルを、誤っているときでさえ、自分が正しいと人間に信じ込ませるのが巧みになるよう仕立てるのだ。
だが最前線は動いている。最近のRubrics as Rewardsという枠組みは、趣味を構造化された確かめられる基準へと分解する。「これは良いか」と問う代わりに、具体的な問いの一群を尋ねるのである。医療推論のベンチマークにおいて、これは31%の改善を達成する。その洞察はこうだ。趣味を丸ごと捉えることはできないが、それを検証できる構成要素へと分解することはできる。判断の全体は検証できなくとも、各々の基準は検証できる。
2023年の終わり、FunSearchというシステムが、この構造の全体を数学の最前線で実証した。それは言語モデルを自動の評価器と組み合わせ、キャップ集合問題に新しい構成を見いだした。二十年来で最大の前進であった。言語モデルが候補を生成した。評価器がそれぞれを、ただ正しいか誤りかではなく、どれほど良いかという豊かな数値の信号で採点した。進化的な探索が最良の発想を組み替えた。その発見はNatureに発表された。
そして研究者たちは、その境界について明言していた。数学的な証明を生成する問題はこの射程の外にある。十分に豊かな採点の信号をどう与えればよいかが不明だからだ。趣味を作れるところでは、発見が起こる。それができないところでは、目を見張る生成は得られても、良いものをもっともらしいものから見分ける術がない。
次に作られるもの
四エンジンモデルは、なぜAIによる自動化が知識労働のスタックを下から上へと進むのかを説明する。それは私のコンパイル命題(Compilation Thesis)が描きながらも十分には説明しきれなかったことだ。
理由は構造的である。抽象のスタックを上るにつれて、つまりコードからアーキテクチャ、戦略へと上るにつれて、仕様ギャップ(Spec Gap、欲しいものを言葉にすることが難しくなる)と投影ギャップ(Projection Gap、質を評価する帯域が狭まる)が、ともに広がる。だからこそ趣味は、コードのためよりも戦略のために作るほうが難しい。戦略の領域がより雑然としているからというだけではない。評価の信号そのものが、明示するのも、伝えるのも、確かめるのも難しくなるからだ。エンジンは抽象が増すほど作りにくくなる。拠って立つ真実が後退していくからである。
コードの層では、四つのエンジンすべてが、他のどの領域よりも実用に近い。生成は強い。評価はテスト、型システム、リンタを通して存在する。実装をめぐる探索はコーディングエージェントの中で活発だ。だからこそコードが最初にコンパイルされて消えていく。
アーキテクチャの層では、趣味は弱く、想像はほとんどない。ここで私は、自分の仕事が変わったことに気づいた。もっとも、それが何へ変わったのかを理解するには、しばらくかかった。あるAIエージェントが、どんなコードレビューも通ったであろうサービスのアーキテクチャを生み出した。そして私は、なぜかを正確には言えぬまま、それが三か月のうちに我々が見ることになる負荷のパターンを生き延びないと分かっていた。システムは、私が明示できる思考をしていた。私は、明示できない思考をしていた。当時の私はこれを言い表す語彙をもたなかった。いまはもつ。その思考が趣味だった。
戦略の層では、趣味も想像も依然として弱く、脆く、組織に固有である。経験を積んだ実践者の判断がなお価値をもつのは、彼らがより多くの事実を知り、より注意深く推論するからではない。何年も決定が展開していくのを見続けて築かれた、評価の本能と心的なモデルをもつからだ。
より深い問題がある。趣味は伝統的に、仕事を実際にこなし、熟練者の評価を受けることで育ってきた。若手の弁護士が準備書面を書き、パートナーがそれに朱を入れ、何年もかけて若手が評価の基準を内面化する。その仕事自体が自動化されると、若手は、評価するだけの経験をもたない出力の検証者になる。趣味を築くフィードバックの過程が断たれる。よりにもよって趣味が最も価値ある認知操作になろうとする、まさにその瞬間に。
想像、すなわち第四のエンジンは、依然として研究の最前線にとどまる。MuZeroの力学ネットワークは未来の状態を圧縮された表現の中で予測し、長い地平ほど精度を落とすが、各段階で探索によって正される。完璧な世界モデルは要らない。短い地平の計画にとって方向だけ使えるものがあればよい。この原理は、ゲームで、タンパク質の折りたたみで(AlphaFold、2024年ノーベル賞)、そして初期の形ながら物理的な力学で(V-JEPA 2、2025年)実証されてきた。だが物理的な予測と戦略的な予測のあいだの隔たりは、途方もなく大きい。知識労働のための想像は、十年単位の最前線である。そして想像が弱いほど、より大きな比重が趣味にのしかかる。おおまかな世界モデルは、MuZeroが示すとおり各段階で探索によって正せる。悪い評価の信号は正せない。探索の全体を誤った方向へ送り出してしまう。
その軌跡には示唆がある。アルファ碁(2016年、ゲーム)からAlphaFold(2020年、生物学、2024年ノーベル賞)へ、そしてFunSearch(2023年、数学、Nature発表)へ。最近のシステムは、この構造が外へと広がりつつあることを示唆する。2025年のASI-ARCHというプレプリントは、人間が設計したベースラインを上回る106の新しいニューラルアーキテクチャを発見した。どの一歩も、より難しい領域へと手を伸ばす。どれも成功するのは、十分な評価の信号が存在するからだ。最前線は、評価の信号が尽きる場所のどこであれ、そこにある。次に攻略されるワークフローは、組織的な判断が比較的安定した基準へと分解できるもの、すなわちコンプライアンス重視の審査、範囲の限られた臨床トリアージ、反復的な財務分析だろう。最後まで残るのは、趣味が分解をまるごと拒むワークフローである。
むすび
バベルの図書館はいまや完璧な司書をもつ。語のあらゆる組み合わせが指先にある。だが司書は、あなたの代わりに木を歩いてはくれない。
2012年、私は主題の階層という無限の木を航行していた。2016年、アルファ碁は盤面という無限の木を航行した。いまや私は、設計上の決定という無限の木を航行するシステムにとっての趣味の関数として日々を過ごしている。評価の判断こそが探索を扱えるものにする信号となる、ループの中の人間としてである。かつて私がモデル化した構造は、いま私が住まう構造である。
その歩みには趣味が要り、趣味とは一つの生涯を一つの判断へと圧縮したものだ。それは形にされるよりも感じ取られる。一世紀前にポアンカレが知っていたとおりに。それは価値ネットワークである。十年前にアルファ碁が実証したとおりに。
語の費用はゼロになった。趣味の費用は、そうではなかった。
¹ “Modeling Topic Hierarchies with the Recursive Chinese Restaurant Process,” CIKM 2012.