The Architecture of Discovery
What AlphaGo revealed about thinking
Borges imagined a library containing every possible book. We built it. Large language models can now generate and retrieve virtually any arrangement of words on demand. The perfect librarian has arrived.
And yet discovery has not been automated. The cost of generating text approaches zero. The cost of genuine insight has not. If every answer is already “in there,” why can’t we just look it up?
Because discovery is not retrieval. It is navigation. You stand at a node in an infinite branching tree. Each choice opens another infinity. You cannot look up the path to the insight you need, because the address of that insight is itself the output of a computation you cannot skip. Verifying an answer, once found, is easy. Finding it is hard.
In 2012, I published a model for navigating exactly this kind of structure: an infinite tree of unbounded depth and width, where the useful signal is not along any single path but distributed across the entire hierarchy.¹ The model’s key insight was that a recursive search, guided at each node by a signal concentrating attention on the most promising branches, could make the infinite tractable. I was modeling topic hierarchies in text corpora. I did not realize I was working on a version of the same problem.
Four years later, a system demonstrated that architecture on a Go board.
1. What Move 37 Knew
Ten years ago today, in the second game of a five-game match against world champion Lee Sedol, AlphaGo placed a stone on the fifth line. The commentators fell silent. Fan Hui, a professional player who had studied AlphaGo for months, could not speak. AlphaGo’s own policy network estimated a 1 in 10,000 probability that any human would play it.
It was beautiful. It was winning. And it was genuinely new.
This was not retrieval. The policy network, trained on 30 million positions from 160,000 human games, rated Move 37 as implausible. If AlphaGo had relied only on its compressed knowledge of human play, the move would never have been considered. It was not brute-force search. Go has roughly 10^170 possible board positions. You cannot search your way to the answer.
It was the product of three cognitive operations working together.
Prediction. The policy network. Over 160,000 human games compressed into a probability distribution over next moves: given this position, what would a strong player do? It narrows roughly 250 legal moves to 5 or 10 plausible ones. This is learned pattern recognition. It says what is likely, not what is good, and that difference turns out to matter enormously.
Taste. The value network. It looks at a board position and outputs a single number: how good is this? It does not say what move to make. It says how to feel about where you are, assigning directional value to an intermediate state without completing the computation.
Search. Monte Carlo Tree Search. Deliberate, sequential exploration of alternatives, guided by prediction (which branches to explore) and taste (which positions to value). Thousands of guided simulations per move. The part of thinking that feels like work.
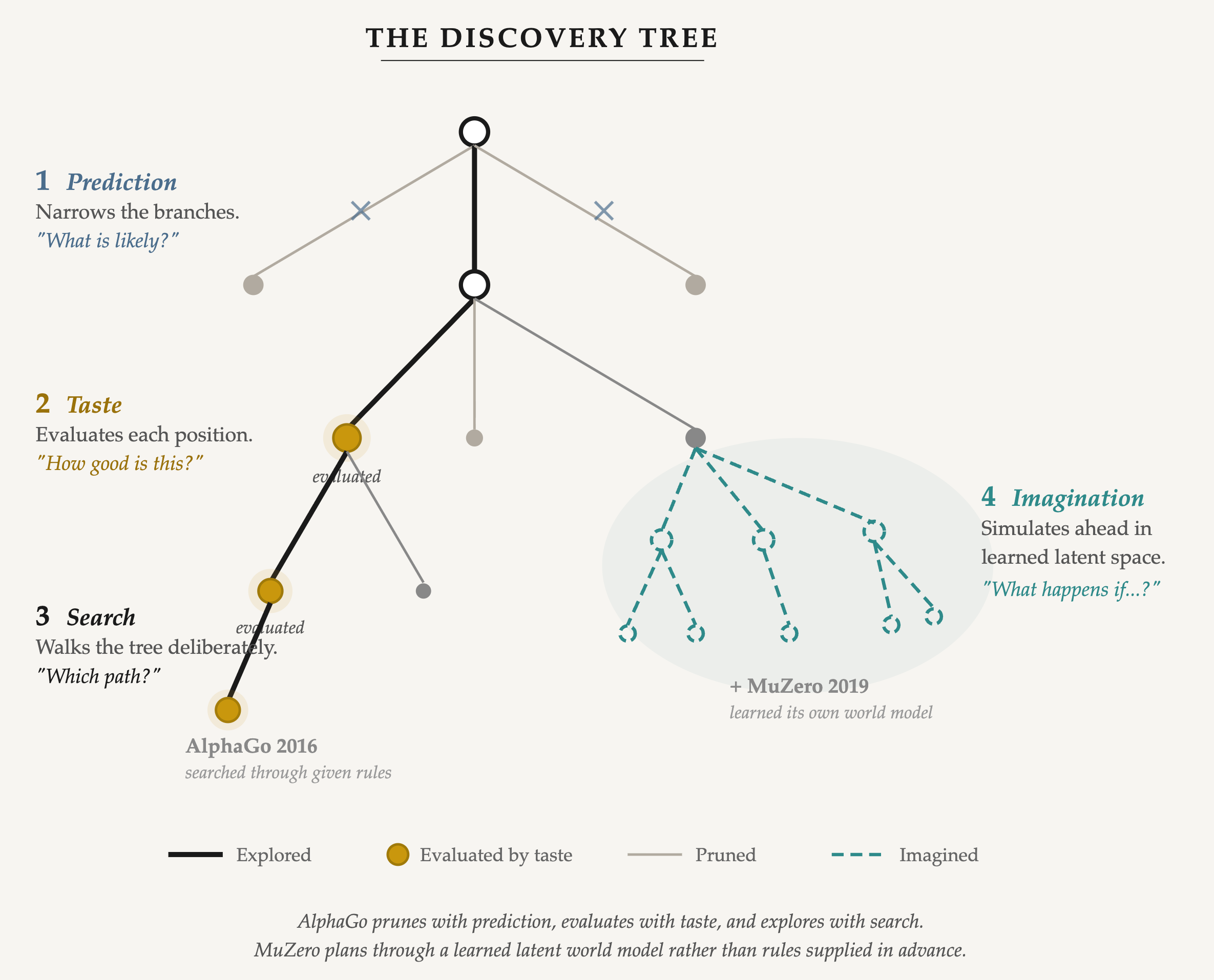
Move 37 happened at their intersection. Prediction rated it as implausible. Search explored it anyway. Taste recognized its quality. Discovery required all three.
And then, in Game 4 of the same match, Lee Sedol played Move 78. Equally improbable. Known afterward as “God’s Touch.” A human, pressured by the machine’s creativity, transcended his own training distribution. He remains the only human ever to beat AlphaGo in a formal match. He retired from professional Go three years later, saying AI “cannot be defeated.” The architecture is not specific to machines or to humans. It appears wherever discovery depends on guided search through a vast space.
A few years after that match, AlphaGo’s successor MuZero changed something fundamental. AlphaGo had searched through a world model we gave it: the explicit rules of Go. MuZero learned one.
Imagination. A learned dynamics model that simulates future states in compressed representations, without ever being given the rules of the game. The system dreams forward in a latent space with no human-readable form. A pre-verbal workspace where consequences play out before they become language. This makes the architecture endogenous. The system no longer plans only through a world model we supply. It learns the model it needs for planning. That is the difference between search over an external world model and planning through a learned latent one.
2. The Proof System and the Discovery System
Current LLMs provide what I will call the proof system: prediction (the base model’s pattern-matched next-token generation) plus search (chain-of-thought reasoning, as built into o3 and DeepSeek R1). These two operations are powerful at finishing a known path: proof, explanation, implementation, analysis. The proof system externalizes its deliberation through token space. Every step is serial, verbal, and auditable. You can read the transcript.
DeepSeek R1 develops chain-of-thought reasoning from pure outcome feedback, no process reward model, no tree search, and spontaneously learns to catch its own mistakes. Impressive. But the reasoning unfolds entirely in natural language. The model has no robust mechanism for holding incompatible fragments in suspension until they cohere.
What is missing is the discovery system: taste (evaluative judgment that prunes and guides without verbalization) plus imagination (simulation of consequences in compressed representations that never pass through the bottleneck of language). In an earlier essay, I argued that discovery operates in a third cognitive mode: slow like System 2 (requiring time and effort) but silent like System 1 (operating on latent representations rather than verbal chains). The four-engine model makes that argument precise. The proof system is prediction and search, externalized through language. The discovery system depends more heavily on latent evaluation and latent simulation, only partially projected into words.
Poincaré mapped this distinction in 1908 with startling precision. His four stages of mathematical creation are preparation, incubation, illumination, and verification. The incubation stage is the one that matters most here. Poincaré described ideas rising “in crowds,” colliding “until pairs interlocked,” all beneath conscious awareness. That is imagination running. The illumination that follows, when the mind surfaces “only certain ones that are harmonious, and, consequently, at once useful and beautiful,” is taste firing. The other two stages, preparation and verification, map straightforwardly to prediction and search.
Seymour Papert at MIT identified the critical structural principle: a “third agent in addition to the conscious and unconscious minds,” somewhat akin to a Freudian censor, “whose job is to scan the changing kaleidoscope of unconscious patterns allowing only those which satisfy its aesthetic criteria to pass through.” That third agent is taste. The value network. The filter on a generative process. It is precisely the architecture of AlphaGo (prediction generates candidates, taste filters them) and, as we will see, precisely the architecture of every system that has achieved genuine discovery since.
The implication is stark. The frontier of what AI can discover is wherever the evaluation signal runs out.
Upstream of these four engines lies an operation the model does not fully capture: generating what should exist before any evaluation is possible. Problem-finding, question-asking, spec-writing before the spec exists. The four engines govern what happens once a search object exists. But taste is the binding constraint on everything downstream of that generative act, and it is the constraint we know how to engineer against.
3. The Taste Bottleneck
Without taste, you are lost in the Library of Babel. You can access everything and find nothing. This is the part most people building with LLMs have not fully absorbed. The value network is what makes AlphaGo’s thousands of search simulations sufficient to navigate a 10^170 state space. Remove it, and the same simulations wander.
The Tree-of-Thought result from 2023 demonstrated this in language. GPT-4 with chain-of-thought prompting solved 4% of Game of 24 tasks. The same model, with tree-structured search guided by self-evaluation, solved 74%. Same model. Same knowledge. The difference was search guided by primitive taste. Even crude taste converts intractable search into tractable search.
Process Reward Models are one leading attempt to build taste for language. They work where verification is cheap: math has checkable answers, code has executable tests. They fail where verification requires the full computation, where “good” depends on context, experience, and consequences you cannot simulate.
The technical obstacles are real. A 2025 paper argued that preference-based training systematically penalizes the exploratory reasoning that makes thinking effective: backtracking, self-correction, messy-but-productive search. Preference data is not just noisy. It can be systematically wrong. And reward hacking compounds the problem: RLHF makes models better at convincing humans they are correct, even when they are wrong.
But the frontier is moving. A recent framework called Rubrics as Rewards decomposes taste into structured, checkable criteria. Instead of asking “is this good?” you ask a battery of specific questions. On medical reasoning benchmarks, this achieves a 31% improvement. The insight: you cannot capture taste holistically, but you can decompose it into verifiable components. Each criterion is checkable even when the whole judgment is not.
In late 2023, a system called FunSearch demonstrated the full architecture at the frontier of mathematics. It paired a language model with an automated evaluator and discovered new constructions for the cap set problem, the largest improvement in twenty years. The LLM generated candidates. The evaluator scored each on a rich numerical signal: not just correct or incorrect, but how good. An evolutionary search recombined the best ideas. The discovery was published in Nature.
And the researchers were explicit about the boundary: the problem of generating mathematical proofs falls outside this scope, because it is unclear how to provide a rich enough scoring signal. Where taste can be built, discovery happens. Where it cannot, you get impressive generation with no way to tell the good from the plausible.
4. What Gets Built Next
The four-engine model explains why AI automation moves bottom-up through the knowledge work stack, something my Compilation Thesis described but could not fully account for.
The reason is structural. As you move up the abstraction stack, from code to architecture to strategy, both the Spec Gap (what you want becomes harder to articulate) and the Projection Gap (the bandwidth for evaluating quality narrows) widen. This is why taste is harder to build for strategy than for code. It is not just that strategic domains are messier. It is that the evaluation signal itself becomes harder to specify, harder to transmit, harder to verify. The engines get harder to build as abstraction increases because the ground truth recedes.
At the code layer, all four engines are closer to operational than in any other domain. Generation is strong. Evaluation exists through tests, type systems, linters. Search over implementations is active in coding agents. This is why code is being compiled away first.
At the architecture layer, taste is weak and imagination is nearly absent. This is where I found my job had changed, though it took me a while to understand what it had changed into. An AI agent produced a service architecture that would have passed any code review. And I knew, without being able to say exactly why, that it would not survive the load patterns we would see in three months. The system was doing the thinking I could specify. I was doing the thinking I could not. I did not have the vocabulary for this at the time. Now I do. That thinking was taste.
At the strategic layer, taste and imagination remain weak, brittle, and highly institution-specific. Senior judgment remains valuable not because experienced practitioners know more facts or reason more carefully, but because they have evaluative instincts and mental models built through years of watching decisions play out.
There is a deeper problem. Taste has traditionally developed through doing the work and receiving expert evaluation. The junior attorney writes briefs, the partner marks them up, and over years the junior internalizes the evaluative standards. When the work itself is automated, the junior becomes a reviewer of output they lack the experience to evaluate. The feedback loop that builds taste is broken, precisely at the moment when taste becomes the most valuable cognitive operation.
Imagination, the fourth engine, remains the research frontier. MuZero’s dynamics network predicts future states in compressed representations, becoming less accurate over longer horizons but corrected by search at each step. You do not need a perfect world model. You need one that is directionally useful for short-horizon planning. This principle has been demonstrated in games, protein folding (AlphaFold, Nobel Prize 2024), and, in early form, physical dynamics (V-JEPA 2, 2025). But the gap between physical prediction and strategic prediction is enormous. Imagination for knowledge work is a decade-scale frontier. And the weaker imagination is, the more weight falls on taste. An approximate world model can be corrected by search at each step, as MuZero demonstrates. A bad evaluation signal cannot. It sends the entire search in the wrong direction.
The trajectory is suggestive: AlphaGo (2016, games) to AlphaFold (2020, biology, Nobel Prize 2024) to FunSearch (2023, mathematics, published in Nature). Recent systems suggest the architecture is extending outward. A 2025 preprint called ASI-ARCH discovered 106 novel neural architectures outperforming human-designed baselines. Each step reaches into a harder domain. Each succeeds because an adequate evaluation signal exists. The frontier is wherever the evaluation signal runs out. The next workflows to crack will be those where institutional judgment can be decomposed into relatively stable rubrics: compliance-heavy review, bounded clinical triage, repetitive financial analysis. The workflows that remain last are those where taste resists decomposition entirely.
Closing
The Library of Babel has a perfect librarian now. Every combination of words is at our fingertips. But the librarian cannot walk the tree for you.
In 2012, I was navigating infinite trees of topic hierarchies. In 2016, AlphaGo navigated infinite trees of board positions. Now I spend my days as the taste function for systems navigating infinite trees of design decisions, the human in the loop whose evaluative judgment is the signal that makes the search tractable. The architecture I once modeled is the architecture I now inhabit.
The walk requires taste, and taste is the compression of a life into a judgment. It is felt rather than formulated, as Poincaré knew a century ago. It is the value network, as AlphaGo demonstrated a decade ago.
The cost of words went to zero. The cost of taste did not.
¹ “Modeling Topic Hierarchies with the Recursive Chinese Restaurant Process,” CIKM 2012.
Concepts Compilation thesis · Four engine model of discovery · Evaluative vs generative judgment · Projection gap